Para el fin de este post, ha sido obtenida una muestra
aleatoria pequeña de la base de datos “CASEN 2009”, la cual ha sido reducida a
1000 observaciones. Los problemas de realizar estimaciones lineales con pocas
observaciones son evidentes, al no permitir a los estimadores converger a sus
valores asintóticos, pero dado el fin netamente demostrativo en esta ocasión
será útil una muestra reducida.
(Para reducir una base a un número aleatorio de
observaciones, puede utilizar el siguiente comando en STATA: Sample 1000 , count)
Ya con nuestra base reducida, realizaremos una estimación lineal para intentar obtener de una manera bastante simple los coeficientes de un modelo donde regresionaremos el salario de un individuo contra sus años de escolaridad, su edad y su género ( hombre o mujer ). De forma que nuestro modelo a estimar será un modelo lineal multivariado de la siguiente forma:
ln(ingreso) = B(0) + B(1)*Escolaridad + B(2)*Edad + B(3)*Género + u
Las
variables utilizadas para este modelo son:
- ln (ingreso) = Logaritmo natural del ingreso
- Escolaridad: Años de educación del individuo
- Edad: Edad del individuo
- Género: Variable dicotómica que toma valores igual a 1 cuando el sujeto es de
género
masculino y 0 cuando el sujeto es de género femenino.
Para
comprender los primeros pasos de cómo instalar la herramienta de análisis de
datos y los componentes básicos de “ESTIMACION.LINEAL” en Excel, puede
encontrar dicha información detallada en un post agregado con anterioridad en
la siguiente dirección:
Estimación lineal en Excel
Es importante destacar que gran parte del trabajo para todos
aquellos rubros que se dedican a crear, manipular e interpretar datos, está
enfocada en comprender como estos están estructurado, sus respectivas
relaciones y sus fortalezas o debilidades, por lo que tan relevante como la operación
misma de los datos, es poder
comprenderlos.
Al momento de realizar una estimación
lineal, la cual es llevada a cabo por el método de “Mínimos Cuadrados
Ordinarios”, son varias las precauciones que deben tomarse antes de llevar a
cabo la estimación lineal, para que los coeficientes obtenido sean insesgados y
eficientes, así como al mismo tiempo la inferencia que hagamos de ella sea
correcta.
Dado que nuestra muestra proviene de los
datos originales provenientes de la encuesta CASEN2009 , veamos como quedan
presentados nuestros datos al acotar la muestra (Las grandes bases de datos,
productos de su tamaño y forma de recopilación, suelen venir en formatos
asignados a programas estadísticos como STATA o SPSS).
De forma que podemos ver que para
nuestras variables discretas (ingreso, escolaridad y edad) tenemos casos en que
existen datos faltantes, los cuales STATA inmediatamente reemplaza con un
punto.
Veamos
qué pasa cuando deseamos incorporar esta
información a nuestra hoja de cálculo de Excel:
De forma que podemos observar como los
datos faltantes en Excel al momento de ingresarlos, son asignados como celdas
vacías, lo cual es un problema si deseamos correr inmediatamente una regresión
lineal, dado que Excel reconoce los campos vacios como no numéricos y no nos
permitirá realizar la estimación, entregando la siguiente advertencia:
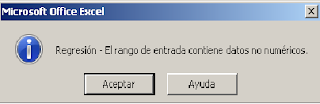
Si deseáramos realizar dicha regresión
lineal en STATA no habría problemas, dado que STATA reconocerá inmediatamente
dichos datos faltantes y no los considera dentro del proceso (O
alternativamente podemos borrar las observaciones utilizando el comando “drop
if variable==.”. Tal consideración en Excel es algo diferente, por el hecho que
Excel no reconoce que cada fila sea una observación y si realizamos una
selección de nuestros datos y apretando F5 vamos a selección especial y
eliminamos las celdas en blanco, lo que haremos será “desplazar” las celdas con información en
reemplazo de aquellas vacías, modificando nuestra información, lo cual no
deseamos.
Para solucionar este problema debemos
manualmente eliminar aquellas observaciones (filas) en que los campos sean
nulos.
Una
vez que solo tenemos celdas no blancas, podemos llevar a cabo la estimación
lineal en Excel, cuyos resultados presentamos en conjunto a los obtenidos en
STATA (comando: reg ln_ingreso escolaridad edad genero):
La primera de estas imágenes corresponde
a los resultados entregados por Excel y la segunda a los entregados por STATA.
Al compararlas podemos ver que de ambos
output podemos obtener:
- Coeficientes de cada una de las variables independientes (Betas) [I]
-Mecanismos para comprobar la significancia de la variable [II]
(i) Valor estadístico t-student
(ii) p-value
(iii) Intervalos de confianza
- Análisis de descomposición de varianza [III]
- Número de observaciones , valor para el test de hipótesis conjunta F ,
valores para el r^2 y
r^2-ajustado.
Para cada uno de los output cada uno de
los ítems mencionados se encuentran indicados en las siguientes imágenes:
Podemos ver que una regresión de todos nuestros datos, entregan los mismo
resultados en ambas plataformas, entonces, ¿Qué diferencia usar Excel o STATA
para análisis de regresiones?
Comando
adicionales a la regresión:
(i)Muchas veces al realizar regresiones, algunos de los supuestos básicos de
mínimos cuadrados ordinarios son quebrantados , ejemplo de esto es el caso de
existencia de heterocedasticidad, en cuyo caso en STATA podemos corregirlo
simplemente utilizando el comando “robust” al final de nuestra regresión,
mientras que en Excel, corregir la heterocedasticidad requiere de ejecutar
manualmente el mecanismo de “mínimos cuadrados ponderados” (dividir cada
observación por el inverso de su error estándar), que aunque es posible de hacer,
es más complicado y requiere de tiempo.
De forma que corregir e identificar los
problemas de comportamiento de nuestros datos (heterocedasticidad, multicolinealidad
y/o no normalidad de los errores) puede ser abordado de manera mucha más
directa utilizando el programa STATA (conociendo los comandos adecuados o
usando el menú alternativamente)
(ii) Otro caso que nos permite realizar
el programa STATA y que en Excel no es simple de realizar a primeras, es la
utilización de factores de expansión. Los factores de expansión son ampliamente
utilizados en datos de corte transversal (CASEN ,EPS , ENE , ELPI,…) donde las
observaciones corresponde sólo a una muestra de la población objetivo , y para
obtener conclusiones a nivel agregado es necesario ponderar cada individuo
según su nivel de representatividad en la población.
Criterios:
Algunas
veces deseamos obtener los coeficientes de una estimación lineal para un
segmento muy específico de la población. Por ejemplo podríamos desear saber
cuan rentable es un año de escolaridad para un individuo mujer, entre 20 y 30
años de la región Metropolitana.
Cada una de estas condiciones son “filtros” que aplicamos a nuestra regresión.
El sistema de análisis de datos de Excel no permite establecer dichas
condiciones ex – ante por lo que si deseamos realizar una regresión para
“Mujeres de entre 20 y 30 años de la región Metropolitana” debemos aislar dicha
información manualmente o usando filtros para cada variable.
La diferencia radica en que en la plataforma STATA los factores mencionados
pueden ser realizados de forma automática en un solo comando sin necesidad de
entrar a modificar ni ordenar la información. Los factores mencionados serían
en un solo paso realizados en STATA de la siguiente forma:

De forma que STATA tiene como ventaja a
Excel, poder dar ciertas opciones y criterios a nuestras regresiones, así como
evitar tener que estar modificando nuestra base cada vez que deseemos una
regresión diferente.
Consideraciones adicionales
Otro tema importante es cuando los
modelos de regresión dejan de ser de forma lineal como los del ejemplo recién
mencionado. Un caso típico es el de “Modelos de probabilidad lineal” llamados
comúnmente modelos PROBIT o LOGIT. Dichos modelos requieren de un proceso de
maximización mediante iteraciones, lo cual STATA realiza automáticamente, pero
que para poder realizar en Excel, es necesario contar con una herramienta
especial llamada “XLSTAT” (o eventualmente podría ser programado mediante
MACROS, dado que requerimos maximizar una función likelihood). Solo para
mostrar la rapidez de obtener una regresión de probabilidad lineal en STATA se
muestra el ejemplo, de cuan probable es que una familia tenga conexión a
internet dependiendo de su nivel de ingreso y nivel educacional (recordar que
en estos modelos lo relevante son los efectos marginales y no los coeficientes
de la regresión en si):

Como comentario final, podemos decir que
todos las formas de regresión (lineal, probabilística, panel, modelos de sesgo
de selección) pueden ser llevadas a Excel mediante programación, macros y utilización de las definiciones funcionales
de cada caso. La ventaja de STATA es que trae incorporadas dichas
programaciones y pueden ser ejecutadas rápidamente conociendo los comandos y
opciones adecuadas
Por otra parte para realizar regresiones
simples (como de series de tiempo o corte transversal) realizadas
frecuentemente en el campo laboral relacionado a las finanzas y/o economía,
Excel ofrece una herramienta simple y rápida de utilizar para obtener los
coeficientes de una empresa dentro del rendimiento de mercado (por ejemplo). Lo
cual da a Excel una ventaja en ser un programa mucho más amigable y fácil que
STATA.
También es necesario mencionar lo que
respecta al análisis de datos, lo que se refiere a detectar y corregir
problemas de los datos como heterocedasticidad, multicolinealidad,
no-normalidad puede ser hechos tanto en Excel como en STATA, donde como ha sido
mencionado durante el post, realizarlos en Excel es posible pero requiere de
mayor número de pasos y tiempo, implicando un mayor grado de dificultad.
Para poder saber cómo realizar todos los
procedimientos específicos de test y regresiones específicas se recomienda
consultar esta “guía de econometría aplicada usando Excel”.
Por tanto como comentario final es posible concluir que en
términos específicos de análisis y manejo de regresiones STATA es un programa mucho más completo, pues es una plataforma diseñada para tales
efectos, pero que requiere de mayor familiarización de sus comandos y modos de
funcionamiento. En cambio Excel es una plataforma de rápido acceso que para
regresiones simples es una herramienta lo suficientemente potente como para ser
utilizada en caso de ser necesaria, pero restringida por el número de datos que
soporta y por que la información este presentada de forma correcta.
Fuente:
Autor: Antonio Acha



 La primera de estas imágenes corresponde a los resultados entregados por Excel y la segunda a los entregados por STATA.Al compararlas podemos ver que de ambos output podemos obtener:
La primera de estas imágenes corresponde a los resultados entregados por Excel y la segunda a los entregados por STATA.Al compararlas podemos ver que de ambos output podemos obtener:
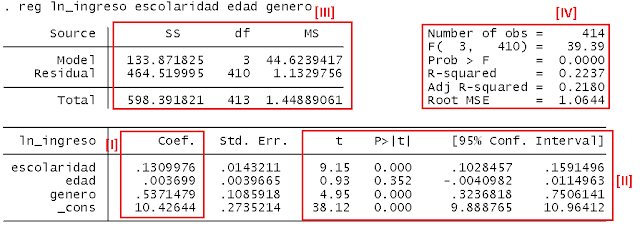 Podemos ver que una regresión de todos nuestros datos, entregan los mismo resultados en ambas plataformas, entonces, ¿Qué diferencia usar Excel o STATA para análisis de regresiones?Comando adicionales a la regresión:
Podemos ver que una regresión de todos nuestros datos, entregan los mismo resultados en ambas plataformas, entonces, ¿Qué diferencia usar Excel o STATA para análisis de regresiones?Comando adicionales a la regresión:








No hay comentarios:
Publicar un comentario